Portfolio




Published on Sep 12, 2017 by Yunwoong Kim on Machine Learning

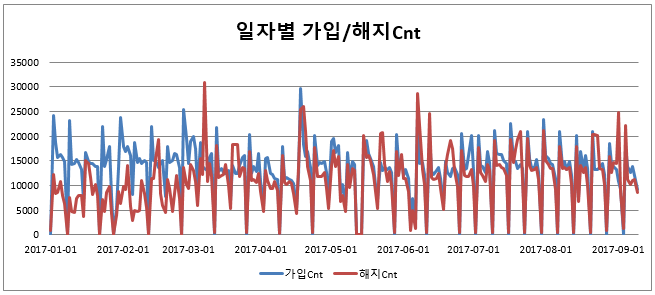
이동통신 시장에서는 고객 측면에서 전환 비용(Switching cost)이 매우 낮기 때문에 고객의 서비스 해지가 빈번하게 일어나고 신규고객이나 타사의 고객을 유치하는 데에는 추가적인 비용이 발생(단말기 보조금 지급, 판촉 행사 비용, 대리점의 수수료 등) 합니다.
Machine Learning Algorism을 활용하여 해지방어활동을 위해 보다 정확하게 고객을 세분화하고 해지가능한 고객을 예측 할 수 있는 모델을 구현하여 다양한 캠페인 진행될 수 있도록 구현하려고 합니다.
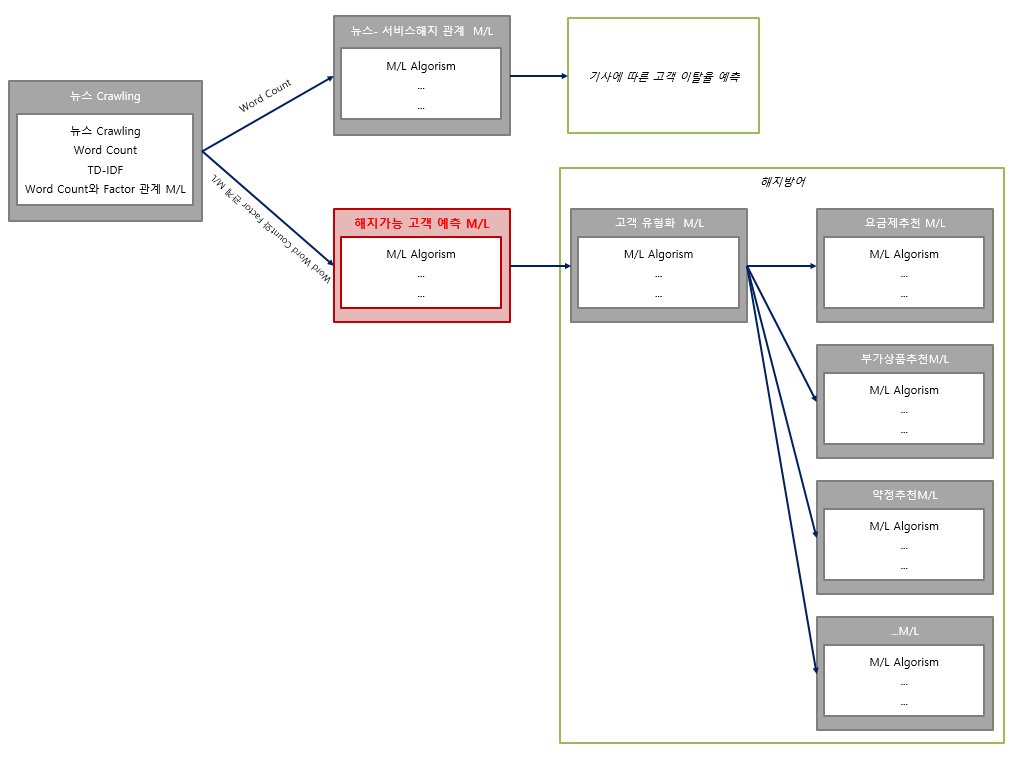
SKT 고객 유지 및 이탈에 영향을 주는 중요변수를 매개로 하여 심층 분석하고 다양한 Machine Learning Algorism을 활용하여 각각의 모델을 구축합니다. 구축된 모델을 비교 평가하고 유형화된 해지 고객을 대상으로 해지 방어 캠페인을 진행하여 고객의 이탈을 방지 할 수 있도록 합니다.
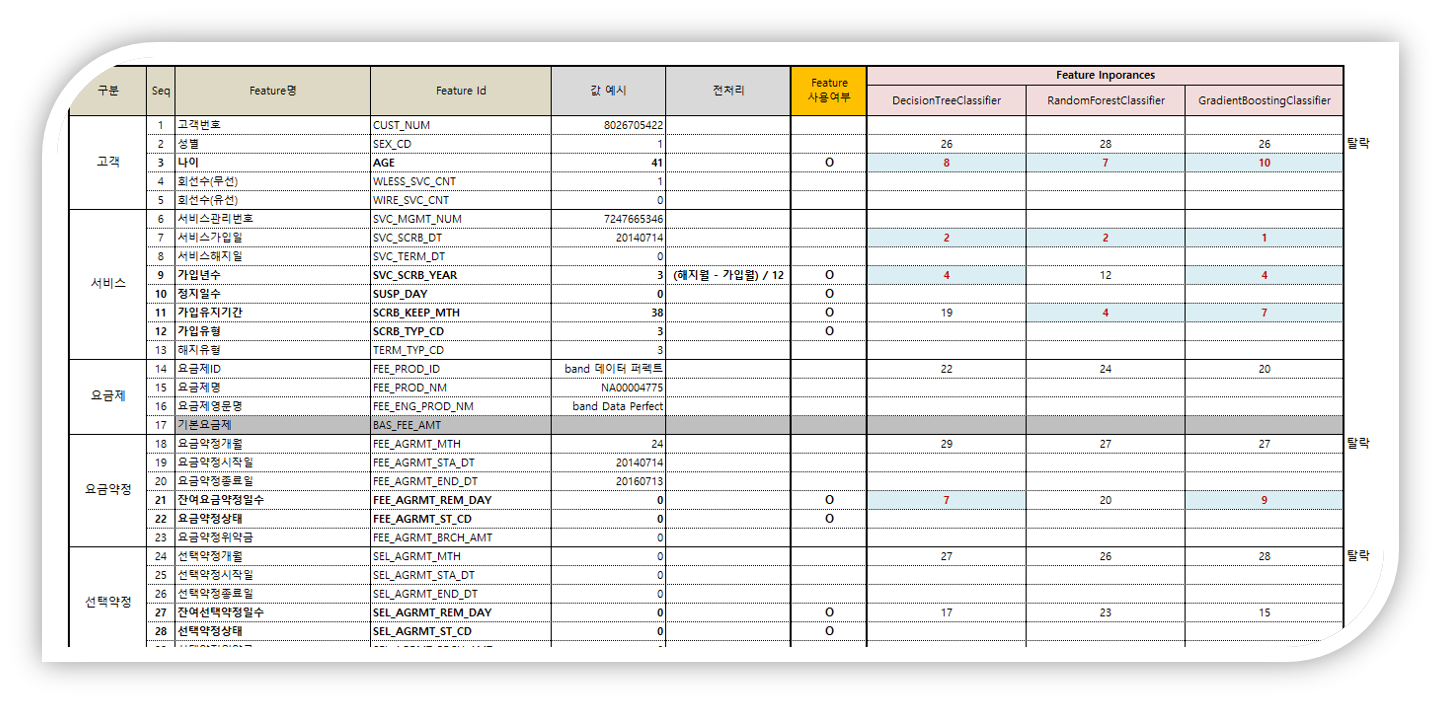
머신러닝의 성능은 어떠한 데이터를 입력하는지에 따라 매우 달라집니다. 충분한 데이터를 모으고 어떤 Feature가 유용한지를 판단해야 합니다. 데이터에 대한 도메인 지식을 활용하여 Feature를 선정합니다.
데이터는 .CSV 파일로 아래와 같은 형태로 준비했습니다.
| CUST_NUM | AGE | SVC_SCRB_YEAR | … | SVC_ST |
|---|---|---|---|---|
| C1 | 63 | 1 | 1 | |
| C2 | 74 | 5 | 0 | |
| … | … | … | … | … |
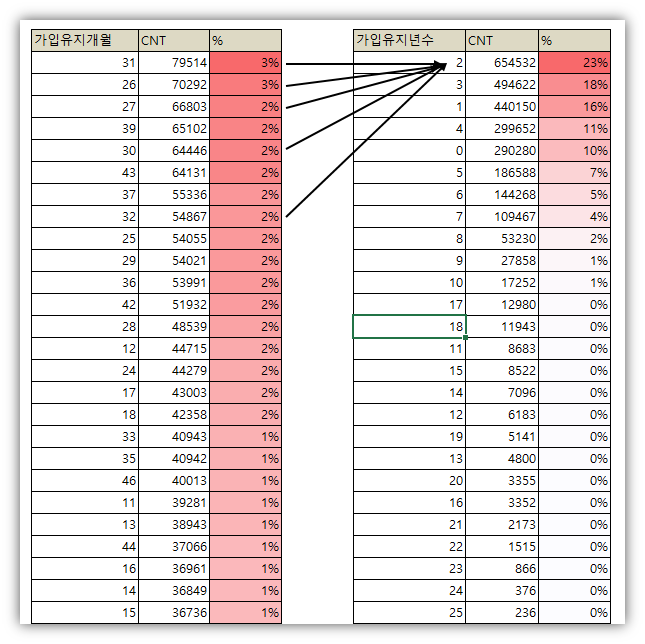
데이터 전처리는 기존의 데이터를 머신러닝 알고리즘에 알맞은 데이터로 바꾸는 과정입니다. 이 전처리 과정은 모델이 생선 된 이후에도 예측하고자 하는 새로운 데이터에도 적용하는 과정입니다. 또한, 전처리 과정을 통해서 더욱더 모델 학습의 성능을 높일 수 있습니다.
특징 중요도(Feature Importance)를 분석하고 특징 중 몇 개를 제거하여 다시 모델을 만들어 성능을 측정하는 일련의 과정을 반복하며 중요도가 높은 특징을 찾아내고 높은 성능의 모델을 만듭니다.
feature_list = [
'SEX_CD','AGE','WLESS_SVC_CNT','WIRE_SVC_CNT',
'SVC_SCRB_YEAR','SCRB_KEEP_MTH', 'SUSP_DAY',
'SCRB_TYP_CD','MTH3_NOT_USED',
'FEE_AGRMT_ST_CD','FEE_AGRMT_REM_DAY',
'SEL_AGRMT_ST_CD','SEL_AGRMT_REM_DAY',
'T_SPRT_AGRMT_AGRMT_ST_CD', 'T_SPRT_AGRMT_REM_DAY',
'MAX_AGRMT_REM_DAY','AGRMT_BRCH_EXISTS_YN',
'AFMLY_COMB_YN',
'BNP_CO_CD',
'EQP_MTHD_CD','EQP_KEEP_MTH',
'BF1_VOICE_DEDP_OVR','BF2_VOICE_DEDP_OVR','BF3_VOICE_DEDP_OVR',
'BF1_LTR_DEDP_OVR','BF2_LTR_DEDP_OVR','BF3_LTR_DEDP_OVR',
'BF1_DATA_DEDP_OVR','BF2_DATA_DEDP_OVR','BF3_DATA_DEDP_OVR',
'BF1_BAS_FEE_DC_RT','BF2_BAS_FEE_DC_RT','BF3_BAS_FEE_DC_RT',
'MBR_GR_CD', 'MBR_EXHST_AMT',
# 'BF1_MTH_VOICE_TC_TMS'
# 'BF1_BAS_FEE_DC_AMT','BF2_BAS_FEE_DC_AMT','BF3_BAS_FEE_DC_AMT',
# 'BF1_BAS_FEE_INV_AMT','BF2_BAS_FEE_INV_AMT','BF3_BAS_FEE_INV_AMT',
]
4가지의 학습모델을 이용하였습니다.
# 결정트리
# tree = DecisionTreeClassifier(random_state=0)
# 과적합인 경우 max_depth로 제한 (연속된 질문을 최대 20개로 제한)
ctree = DecisionTreeClassifier(max_depth=20, random_state=0)
ctree.fit(train_data_std, train_label)
ctree_pre = ctree.predict(test_data_std)
# 랜덤 포레스트
# n_estimators는 생성할 의사결정트리의 개수(k)
# n_jobs는 학습을 수행하기 위해 CPU코어2개를 병렬로 활용
forest = RandomForestClassifier(criterion='entropy', n_estimators=20, n_jobs=2, random_state=2)
forest.fit(train_data, train_label)
forest_pre = forest.predict(test_data)
# 그래디언트 부스팅 회귀 트리
gbrt = GradientBoostingClassifier(random_state=0)
gbrt.fit(train_data, train_label)
gbrt_pre = gbrt.predict(test_data)
# 신경망
mlp = MLPClassifier(max_iter=1000, random_state=0)
mlp.fit(train_data, train_label)
mlp_pre = mlp.predict(test_data)
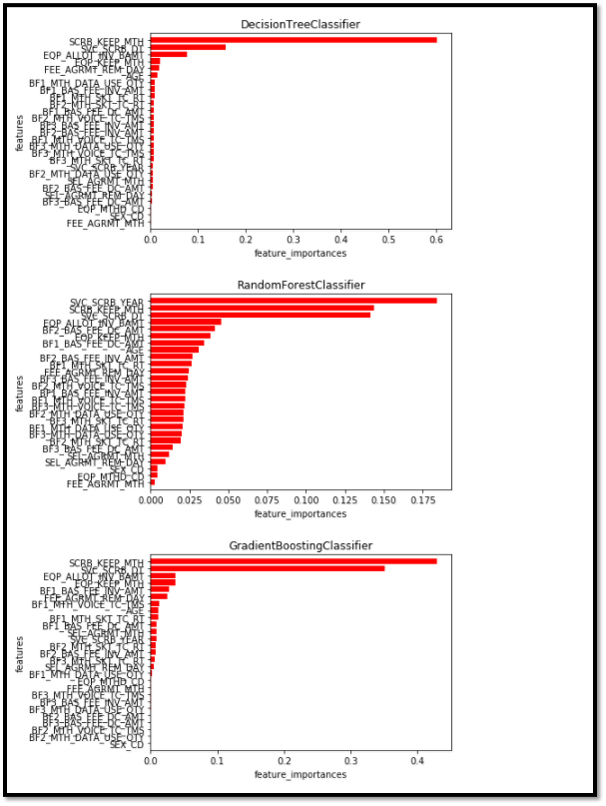
- DecisionTreeClassifier
훈련 세트 점수: 0.39
테스트 세트 점수: 0.39
- RandomForestClassifier
훈련 세트 점수: 1.00
테스트 세트 점수: 0.80
테스트 개수:66643, 오류개수:13159
- GradientBoostingClassifier
훈련 세트 점수: 0.80
테스트 세트 점수: 0.80
- MLPClassifier
훈련 세트 점수: 0.74
테스트 세트 점수: 0.74
테스트 개수:66643, 오류개수:17095
cust1 = pre_csv_data[pre_csv['CUST_NUM']=='C1311']
prediction = mlp.predict(cust1)
pre_rt = mlp.predict_proba(cust1)
print ("예측 : {}" .format(prediction))
print ("예측한 결과 : {}" .format(result_dataset['SVC_ST_NM'][prediction]))
print ("가입유지 확률 : {:.2f} %" .format(pre_rt[0][0] * 100))
print ("해지 확률 : {:.2f} %" .format(pre_rt[0][1] * 100))
예측 : [1]
예측한 결과 : ['해지예상']
가입유지 확률 : 25.08 %
해지 확률 : 74.92 %
분석결과
분석결과를 들여다보면 꼭 머신러닝과 특징 분석 없이도 할 수 있는 당연한 이야기입니다. 그리고 더 중요한 것은 특정 Feature (사용연수와 단말기사용기간) 에 의해 결과가 결정 된다는 것입니다.
예측결과를 0(유지)과 1(해지)로 나타내니 조금 허무하긴 합니다.
그래서 UI를 포함하여 개발을 해보았습니다. 해지예측모델 역시 긍정오류, 부정오류가 모두 존재하기때문에 이러한 모델에 높은 의존도로 업무에 적용하기보다는 이탈 방지를 위한 캠페인 활동 영역에 활용하면 좋을 것 같습니다. 해지를 예측한 결과가 부정오류이거나 긍정오류여도 그 결과에 의한 캠페인 활동은 큰 문제는 없기때문입니다.
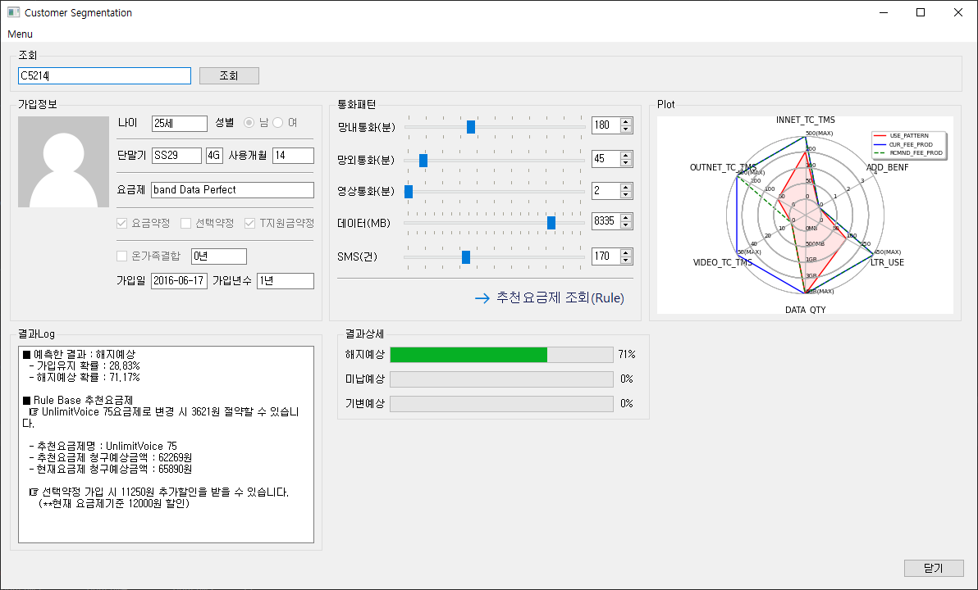
그래프는 위닝일레븐 축구게임에서 선수의 성향처럼 고객의 사용패턴을 표시하였는데, 재미난 사실은 프로그램을 본 사람들이 머신러닝을 통한 결과보다 그래프에 더 관심을 보입니다.