Portfolio




Published on May 31, 2019 by Yunwoong Kim on OCR OPTICAL CHARACTER RECOGNITION DEEPLEARNING


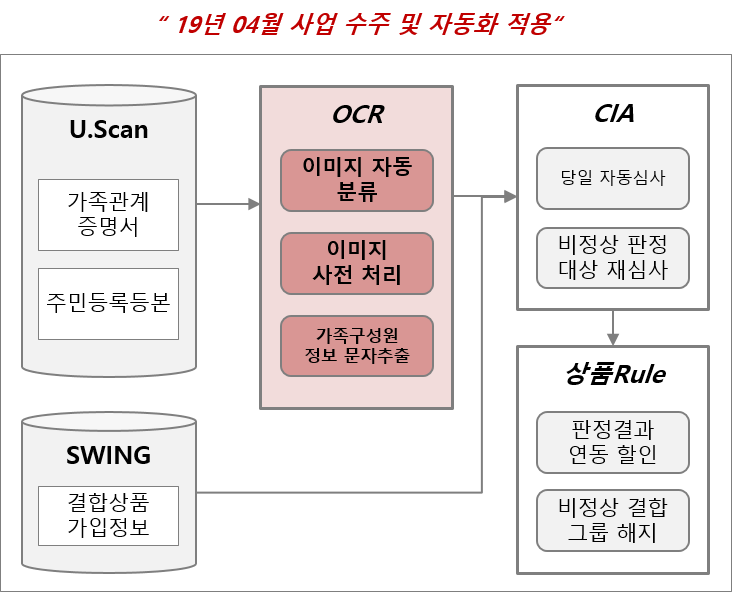
Python으로 작성되었으며 그래픽 인터페이스에 PyQt를 사용합니다. OCR엔진은 Tesseract 오픈소스를 사용하였습니다. 핵심 기술은 어떠한 OCR엔진을 사용하더라도 높은 인식율을 보장 할 수 있도록 분류하고 이미지를 전처리후 OCR을 수행하려는 범위를 자동으로 추출하는 것입니다.
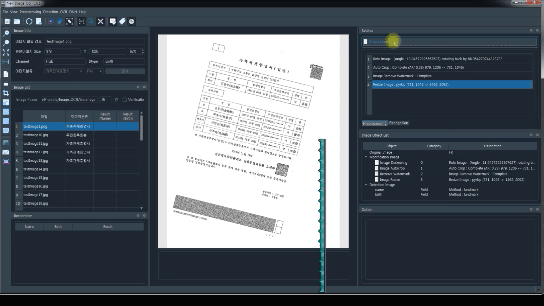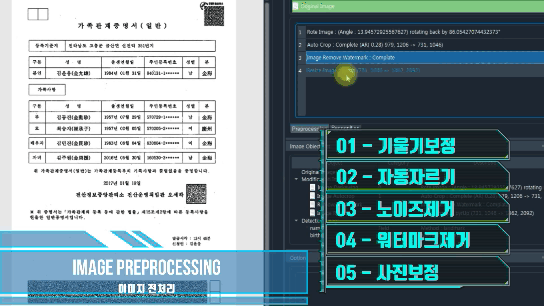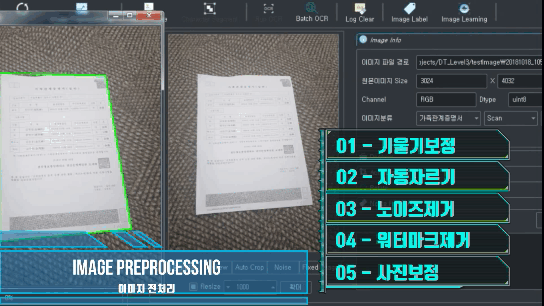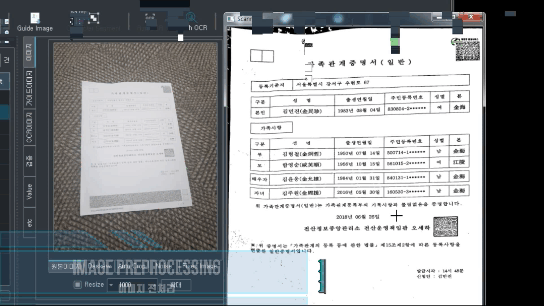
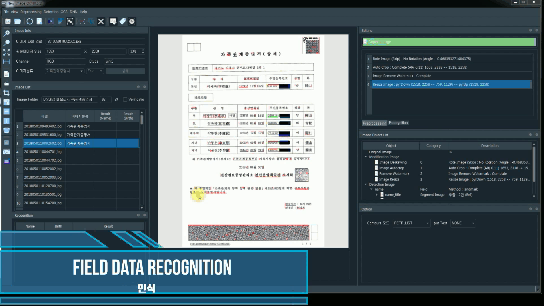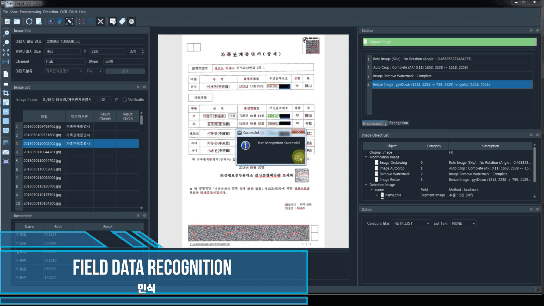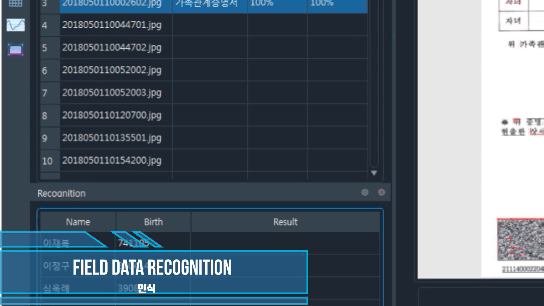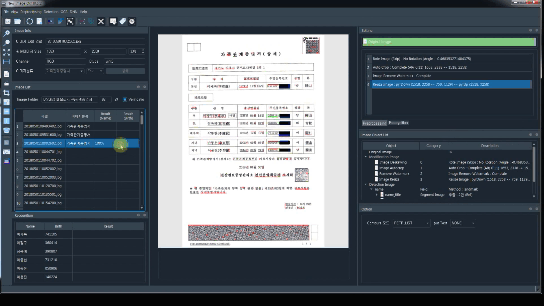
Image를 Load하여 OCR결과를 확인하고 분석하기 위한 GUI를 제공
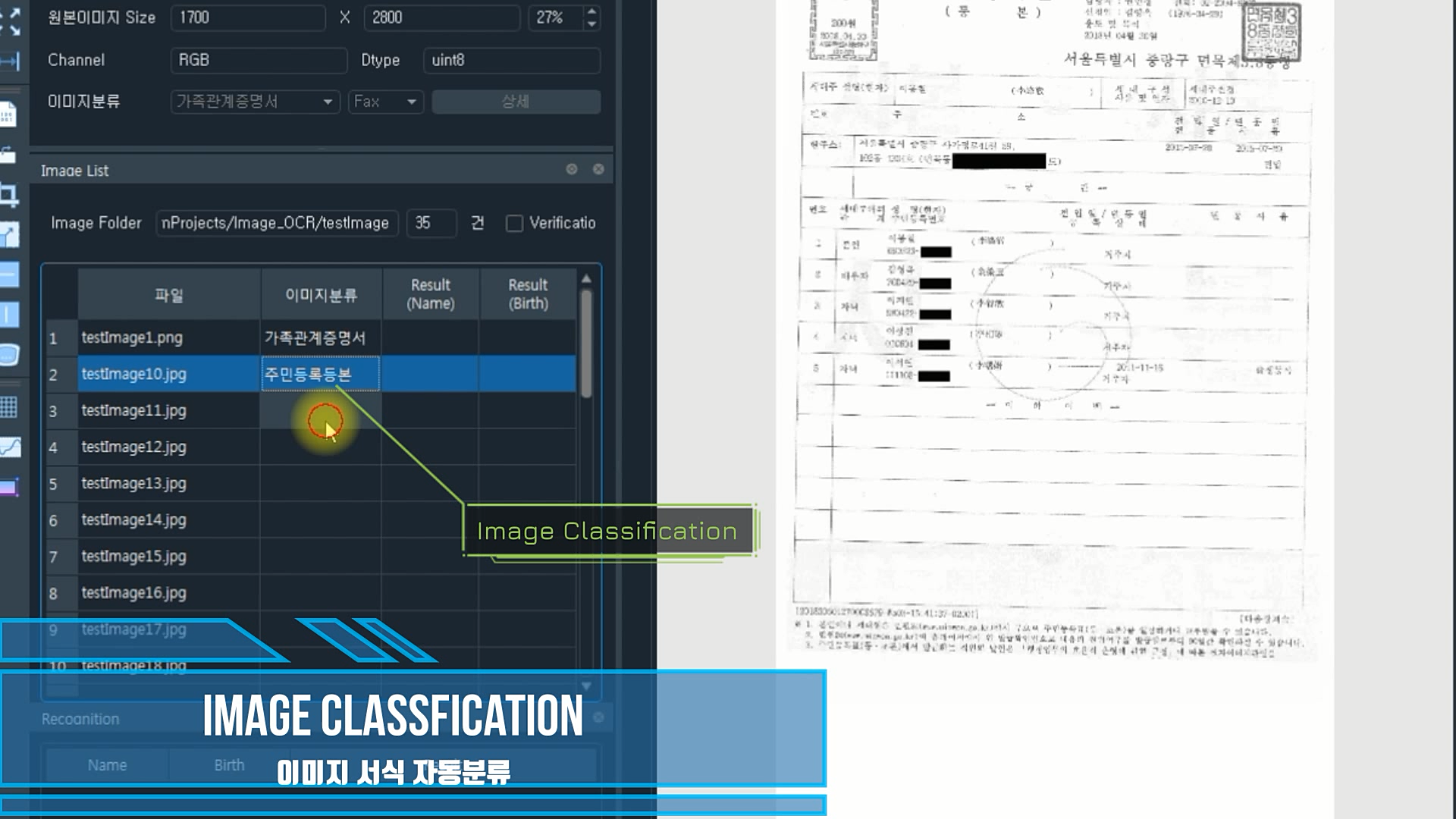
이미지가 Load되면 DeepLearning으로 학습된 Model을 통해 자동으로 서식지가 분류
이미지를 입력 받아서 D/L Model을 기반으로 서식지를 자동으로 분류합니다. (가족관계증명, 주민등록등본, 기타)
이미지 전처리 (Crop, Rotate, Nose..)
이미지의 기울기를 보정
- 왜곡(낙서, 구김, 빛등)으로 인해 기울기에 영향이 생길 수 있어 입력한 angle 값 이하는 보정하지 않음
# gubun :** 'Image Deskewing'
# angle :** Skip below the entered angle
option = [{'gubun': 'Image Deskewing', 'angle': 1}]
ocrImg.modImg.addImgApplyList(option)
ocrImg.modImg.imgCompareShow()

이미지 자동 자르기
- 이미지에서 불필요한 영역 자르기
# gubun : Image Autocrop
# aspectRatio :입력된 aspect ratio(종횡비) 보다 낮은 경우 화질이 좋지 못해서 Cutting 영역을 잡을 수 없기때문에 Skip 처리함
# threshold1 : Hysteresis Thredsholding 작업에서의 min 값
# threshold2 : Hysteresis Thredsholding 작업에서의 max 값
option = [{'gubun': 'Image Autocrop', 'aspectRatio': 0.8, 'threshold1': 100, 'threshold2': 100}]
ocrImg.modImg.addImgApplyList(option)
ocrImg.modImg.imgCompareShow()

워터마크 제거
option = [{'gubun': 'Remove Watermark', 'alpha': 2.0, 'beta':220}]
ocrImg.modImg.addImgApplyList(option)
ocrImg.modImg.imgCompareShow()

이미지 사이즈 조정
- cv2.pyrDown() 과 cv2.pyrUp() 함수를 사용하여 이미지를 축소, 확장
- 가장 아래에 가장 큰 해상도를 놓고 점점 줄여가면서 쌓아가는 형태
# gubun : Image Resize
# resizeCl : resize 구분값 (pyrDown, pyrUp, Auto)
option = [{'gubun': 'Image Resize', 'resizeCl':'Auto'}]
ocrImg.modImg.addImgApplyList(option)
ocrImg.modImg.imgCompareShow()

가로축, 세로축 라인 제거
option = [{'gubun': 'Image RemoveHLine', 'horizontalsize': 30}]
ocrImg.modImg.addImgApplyList(option)
ocrImg.modImg.imgCompareShow()
option = [{'gubun': 'Image RemoveVLine', 'verticalsize': 50}]
ocrImg.modImg.addImgApplyList(option)
ocrImg.modImg.imgCompareShow()

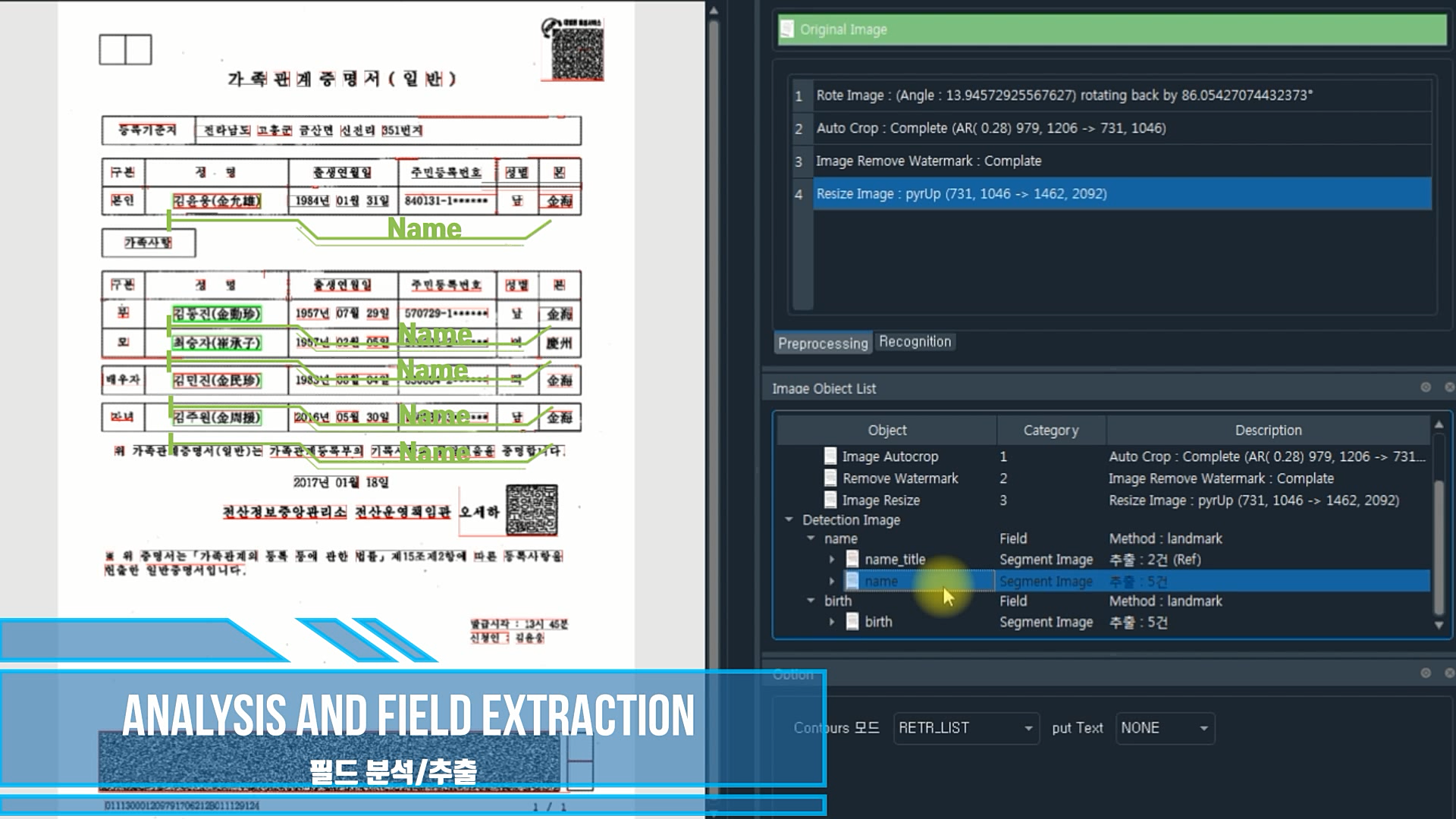
추출 영역 탐지
가이드 이미지를 생성하여 원하는 영역을 추출
ocrImg.detectionField.segmentation(findFieldInfo=fieldInfo, flag='WHY')
ocrImg.detectionField.imgShow(field='name', debug=False)
ocrImg.addDetectionImg(fieldInfo=fieldInfo)
ocrImg.detectionField.imgShow(field='birth')


찾아낸 영역을 추출하여 하나의 이미지로 병합
ocrImg.detectionField.cropImgShow(field='name')
ocrImg.detectionField.cropMergeImgShow(field='name')

인식
인식은 Tesseract OCR 엔진을 사용하며 N개의 프로세스로 수행이 가능
ocrImg.recogTesserOCR(field='name', imgType='cropMergeImg', segmode='-psm 6', ocrmode='kor', process='01', gray=False)
ocrImg.recogResult
[{'field': 'name', 'result': ['이희', '이학승', '정정옥', '성기복', '성광현', '성현선', '성상현']}]

다른 서식의 문서도 가능
Image_OCR/
├── libs/
| └── ocrImage.py # OCR Image Class
| └── modifiedImage.py # Modified Image Class
| └── classification/
| | └── classificationDialog.py # source code for the Classification
| | └── classify.py # Image document classification
| | └── VGGNET_adam_ocr_classification.model # classification model
| | └── VGGNET_adam_ocr_classification.pickle # classification labels
| └── preprocessing/
| | └── preprocessing.py # Image preprocessing
| └── detection/
| | └── detection_landmark.py # detect via landmark
| | └── guideImage.py # Guide Image Class
| | └── segmentation.py # Segmentation Image Class
| | └── landmark/
| | | └── landmark.ini # landmark file
| | | └── doc_fc_name.py # Family certificate document (Name)
| | | └── doc_rr_nameTitle.py # Resident registration document (Title)
| | | └── doc_rr_nameTitle.py # Resident registration document (Name)
| └── recognition/
| | └── recognitionTesseract.py # text recognition
| | └── Tesseract-OCR/ # tesseract installation directory
├── UI/
| └── icon/
| └── NewImageOcr_0.5.1.ui
| └── DetectionField_0.1.1.ui
| └── NewImageOcr_0.5.1.ui
| └── Preprocessing_0.1.1.ui
| └── canvas.py
| └── labelDialog.py
| └── preprocessingDialog.py
| └── detectionFieldDialog.py
| └── lib.py
| └── shape.py
| └── ustr.py
├── result/ # direcotry for the Ocr results
├── sol_csv/ # directory for scoring
├── New_Image_Ocr_0.5.1.py # source code for the Main GUI
├── res_rc.py # pyqt Resource File
└── config.ini # config file